 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Inductive Biases for Multivariate Time-Series Anomaly Detection with a Robust Multi-View Channel-Graph Detector
May 27, 2026We present a unified experiment, analysis, and benchmark study of multivariate time-series (MTS) anomaly detection. Ten family-representative detectors -- spanning statistical, reconstruction, association, frequency, and generic-transformer families -- are evaluated on five datasets (SMD, MSL, SMAP, PSM, and MSDS) under effectiveness, efficiency, robustness, and cross-dataset generalisation. All methods share the same windowing, scoring, hardware, and metric protocols. Effectiveness, ablation, and robustness use three random seeds; cross-dataset transfer uses seed~0 because each extra seed requires $250$ source-target evaluations. The benchmark yields three method-independent findings: no single-bias baseline dominates; absolute perturbation VUS-ROC is more informative than retention ratios; and MSDS behaves as an event-dense deployment workload rather than a sparse point-anomaly benchmark. Under this protocol we also introduce \ours{}, an adaptive detector family combining a NOTEARS-constrained directed channel-graph view with optional patch-attention and temporal-association views. \ours{} achieves the best macro-average VUS-ROC ($0.675$, $+5.1$~pt over the second-best LSTM-AE), ranks first overall, and reaches the top-3 on all five datasets. Its wins on MSL and MSDS are narrow, while its average and robustness gains are larger: under the same three-seed robustness protocol for every method, it obtains the strongest absolute VUS-ROC across noise, channel dropout, and time-shift perturbations. We release the MSDS preprocessing protocol, configurations, scripts, and seed-level metric dumps.
KIO-planner: Attention-Guided Single-Stage Motion Planning with Dual Mapping for UAV Navigation
May 19, 2026Autonomous UAV flight in confined, wall-dense environments requires low-latency and reliable motion planning under strict safety constraints. Traditional optimization-based planners suffer from mapping latency and easily fall into local minima when navigating through dense structural obstacles. Meanwhile, existing end-to-end learning methods struggle to extract fine-grained geometric features from raw depth images and lack hard kinodynamic constraints, leading to unpredictable collisions near walls. To address these issues, we propose KIO-planner, an attention-guided single-stage trajectory planning framework. First, we integrate a Convolutional Block Attention Module (CBAM) into the perception backbone to adaptively focus on critical structural edges and traversable space. Second, we introduce a novel Dual Mapping mechanism--comprising physical bounds activation and a deterministic Geometric Safety Shield in the depth-pixel space--to enforce kinodynamic feasibility and collision-free flight without global map fusion. Extensive high-fidelity simulated experiments demonstrate that KIO-planner enables highly agile navigation at speeds up to 3.0 m/s. Compared to the state-of-the-art baseline, KIO-planner achieves lower inference latency (approximately 24 ms) and generates significantly smoother trajectories, reducing control cost by 28.4%. Most notably, our Dual Mapping substantially increases the worst-case safety margin, measured by minimum distance to obstacles, from 0.48 m to 0.76 m, ensuring fast, smooth, and safer navigation in highly constrained environments.
TSNN: A Non-parametric and Interpretable Framework for Traffic Time Series Forecasting
May 09, 2026Although many complex models were proposed to analyze time series data, some studies have demonstrated remarkable performance with simpler structures. A recent study proposed a non-parametric framework for 3D point cloud classification, which has the potential to be adapted for time series forecasting and enable interpretability. Inspired by the previous works, we present TSNN, a non-parametric and interpretable framework for traffic time series forecasting. TSNN consists of multiple layers that decouple the time series by matching the entries in a memory bank, where the memory bank is constructed using a similar matching process within the training set. It leverages the periodicity in traffic data to enhance forecasting accuracy while maintaining a simple model architecture. The proposed model operates without trainable parameters, preserving its inherent interpretability. In the experiments, TSNN achieves competitive performance compared to the typical deep learning models in four real-world traffic flow datasets. We also visualize the decoupling process to show the effectiveness of the components. Finally, we demonstrate the interpretability of the model and illustrate the contribution of each time step within the memory bank.
SAGA: A Robust Self-Attention and Goal-Aware Anchor-based Planner for Safe UAV Autonomous Navigation
May 04, 2026Agile unmanned aerial vehicle (UAV) navigation in cluttered environments demands a planning architecture that is both computationally efficient and structurally expressive enough to reason over multiple feasible motions. This paper presents SAGA, a robust self-attention and goal-aware anchor-based planner for safe UAV autonomous navigation. SAGA formulates local planning as a one-stage joint regression-and-ranking problem over a fixed lattice of motion anchors. Given a depth image and a body-frame motion state, the planner predicts refined terminal states and planning scores for all anchors in a single forward pass, after which the best candidate is decoded into a dynamically feasible trajectory. The key idea of SAGA is to transform anchor-aligned features into geometry-aware tokens and perform cross-anchor global reasoning with self-attention. To preserve directional structure in the token space, we further introduce a polar positional encoding derived from anchor yaw and pitch. In addition, a goal-aware modulation module injects velocity, acceleration, and target information into the token representation before final score prediction. Experiments in cluttered pillar-map environments under maximum speed settings of 2.0, 3.0, and 4.0~m/s show that SAGA consistently achieves a 100\% success rate, while YOPO drops from 90.91\% to 62.50\%, Ego-planner from 71.43\% to 52.63\%, and Fast-planner from 52.63\% to 38.46\%. Under the 4.0~m/s maximum speed setting, SAGA also improves average safety from 1.9843~m to 2.3888~m and minimum safety from 0.4390~m to 0.7576~m over YOPO, while reducing total flight time from 40.4631~s to 27.4901~s. The comparison with SAGA w/o PPE further shows that explicit polar positional encoding is critical for stable cross-anchor reasoning and safe passage selection in cluttered scenes.
Analysis of the Two-Step Heterogeneous Transfer Learning for Laryngeal Blood Vessel Classification: Issue and Improvement
Mar 05, 2024



Transferring features learned from natural to medical images for classification is common. However, challenges arise due to the scarcity of certain medical image types and the feature disparities between natural and medical images. Two-step transfer learning has been recognized as a promising solution for this issue. However, choosing an appropriate intermediate domain would be critical in further improving the classification performance. In this work, we explore the effectiveness of using color fundus photographs of the diabetic retina dataset as an intermediate domain for two-step heterogeneous learning (THTL) to classify laryngeal vascular images with nine deep-learning models. Experiment results confirm that although the images in both the intermediate and target domains share vascularized characteristics, the accuracy is drastically reduced compared to one-step transfer learning, where only the last layer is fine-tuned (e.g., ResNet18 drops 14.7%, ResNet50 drops 14.8%). By analyzing the Layer Class Activation Maps (LayerCAM), we uncover a novel finding that the prevalent radial vascular pattern in the intermediate domain prevents learning the features of twisted and tangled vessels that distinguish the malignant class in the target domain. To address the performance drop, we propose the Step-Wise Fine-Tuning (SWFT) method on ResNet in the second step of THTL, resulting in substantial accuracy improvements. Compared to THTL's second step, where only the last layer is fine-tuned, accuracy increases by 26.1% for ResNet18 and 20.4% for ResNet50. Additionally, compared to training from scratch, using ImageNet as the source domain could slightly improve classification performance for laryngeal vascular, but the differences are insignificant.
Category-wise Fine-Tuning: Resisting Incorrect Pseudo-Labels in Multi-Label Image Classification with Partial Labels
Jan 30, 2024



Large-scale image datasets are often partially labeled, where only a few categories' labels are known for each image. Assigning pseudo-labels to unknown labels to gain additional training signals has become prevalent for training deep classification models. However, some pseudo-labels are inevitably incorrect, leading to a notable decline in the model classification performance. In this paper, we propose a novel method called Category-wise Fine-Tuning (CFT), aiming to reduce model inaccuracies caused by the wrong pseudo-labels. In particular, CFT employs known labels without pseudo-labels to fine-tune the logistic regressions of trained models individually to calibrate each category's model predictions. Genetic Algorithm, seldom used for training deep models, is also utilized in CFT to maximize the classification performance directly. CFT is applied to well-trained models, unlike most existing methods that train models from scratch. Hence, CFT is general and compatible with models trained with different methods and schemes, as demonstrated through extensive experiments. CFT requires only a few seconds for each category for calibration with consumer-grade GPUs. We achieve state-of-the-art results on three benchmarking datasets, including the CheXpert chest X-ray competition dataset (ensemble mAUC 93.33%, single model 91.82%), partially labeled MS-COCO (average mAP 83.69%), and Open Image V3 (mAP 85.31%), outperforming the previous bests by 0.28%, 2.21%, 2.50%, and 0.91%, respectively. The single model on CheXpert has been officially evaluated by the competition server, endorsing the correctness of the result. The outstanding results and generalizability indicate that CFT could be substantial and prevalent for classification model development. Code is available at: https://github.com/maxium0526/category-wise-fine-tuning.
A Multiple Classifier Approach for Concatenate-Designed Neural Networks
Jan 14, 2021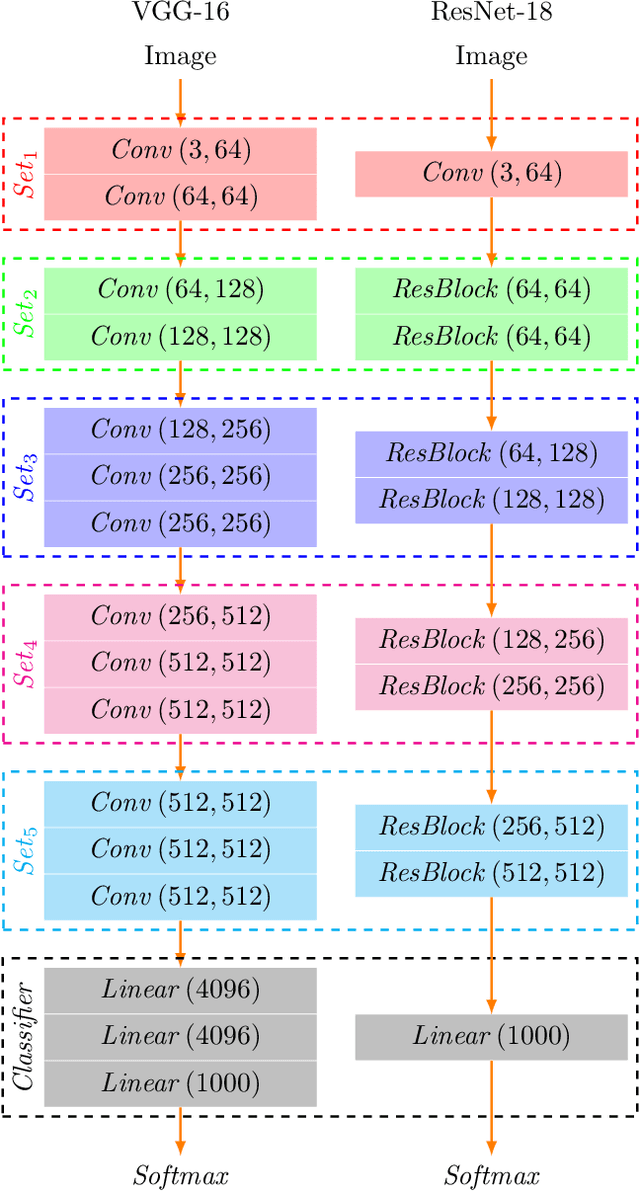
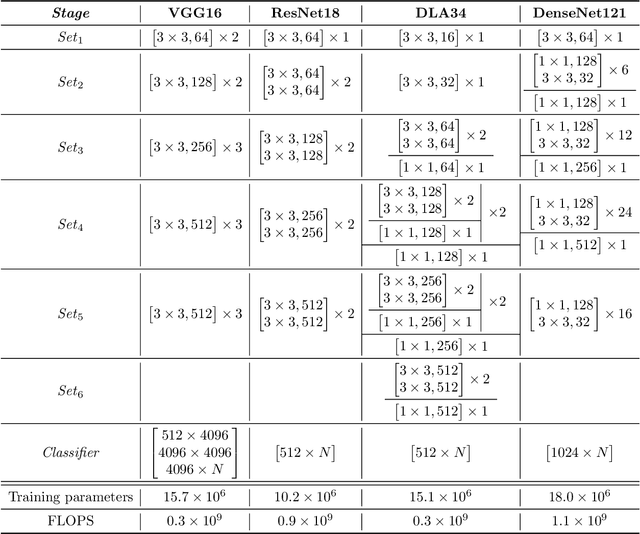
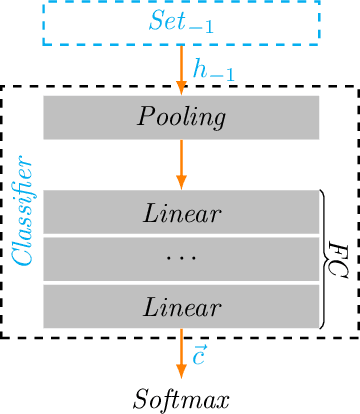
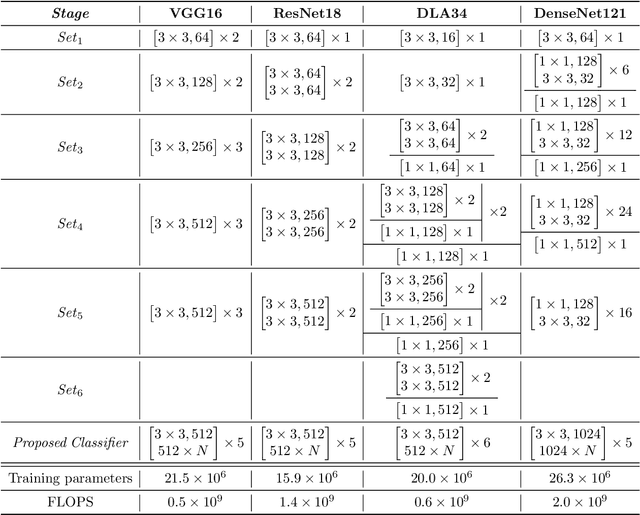
This article introduces a multiple classifier method to improve the performance of concatenate-designed neural networks, such as ResNet and DenseNet, with the purpose to alleviate the pressure on the final classifier. We give the design of the classifiers, which collects the features produced between the network sets, and present the constituent layers and the activation function for the classifiers, to calculate the classification score of each classifier. We use the L2 normalization method to obtain the classifier score instead of the Softmax normalization. We also determine the conditions that can enhance convergence. As a result, the proposed classifiers are able to improve the accuracy in the experimental cases significantly, and show that the method not only has better performance than the original models, but also produces faster convergence. Moreover, our classifiers are general and can be applied to all classification related concatenate-designed network models.